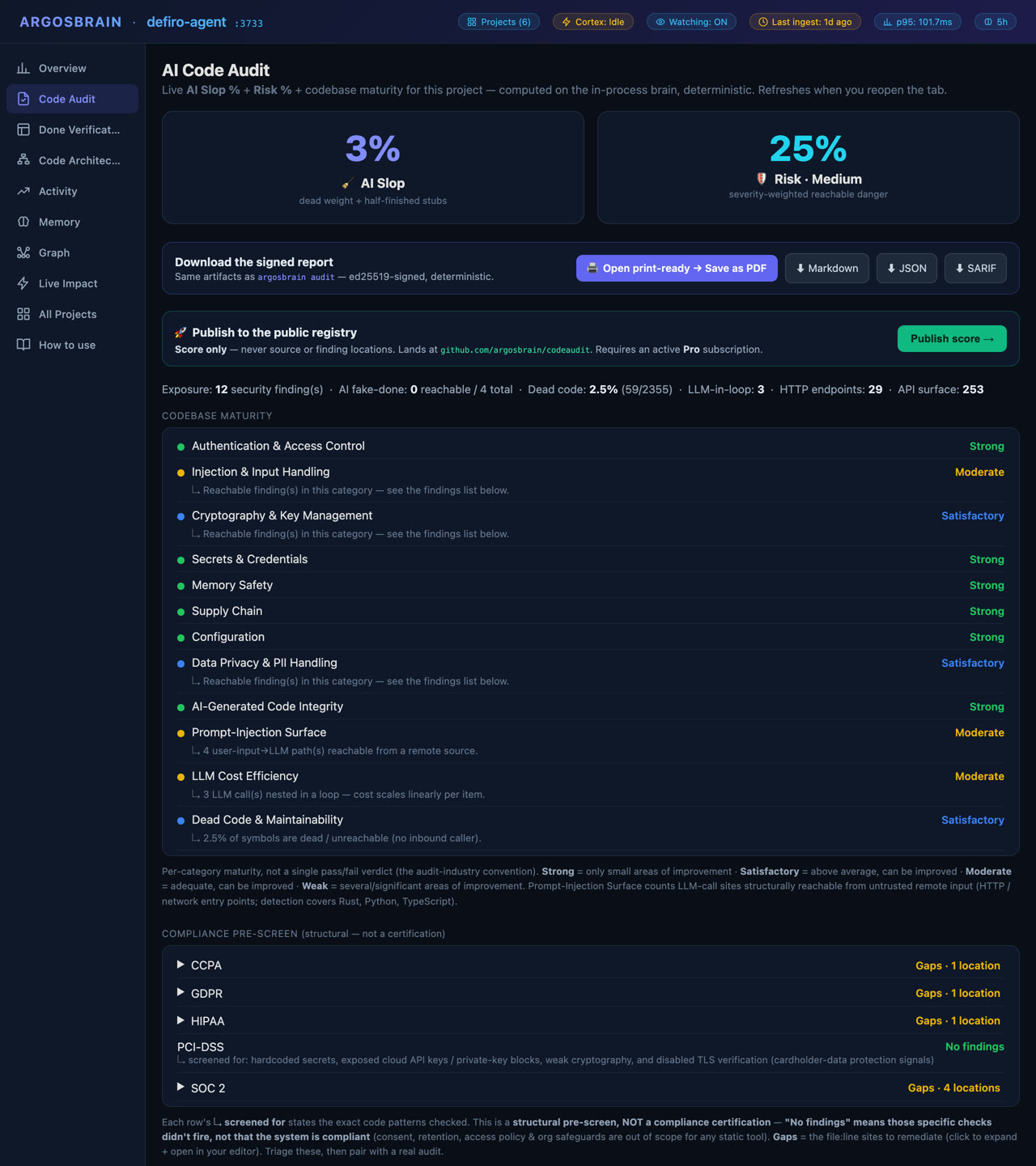
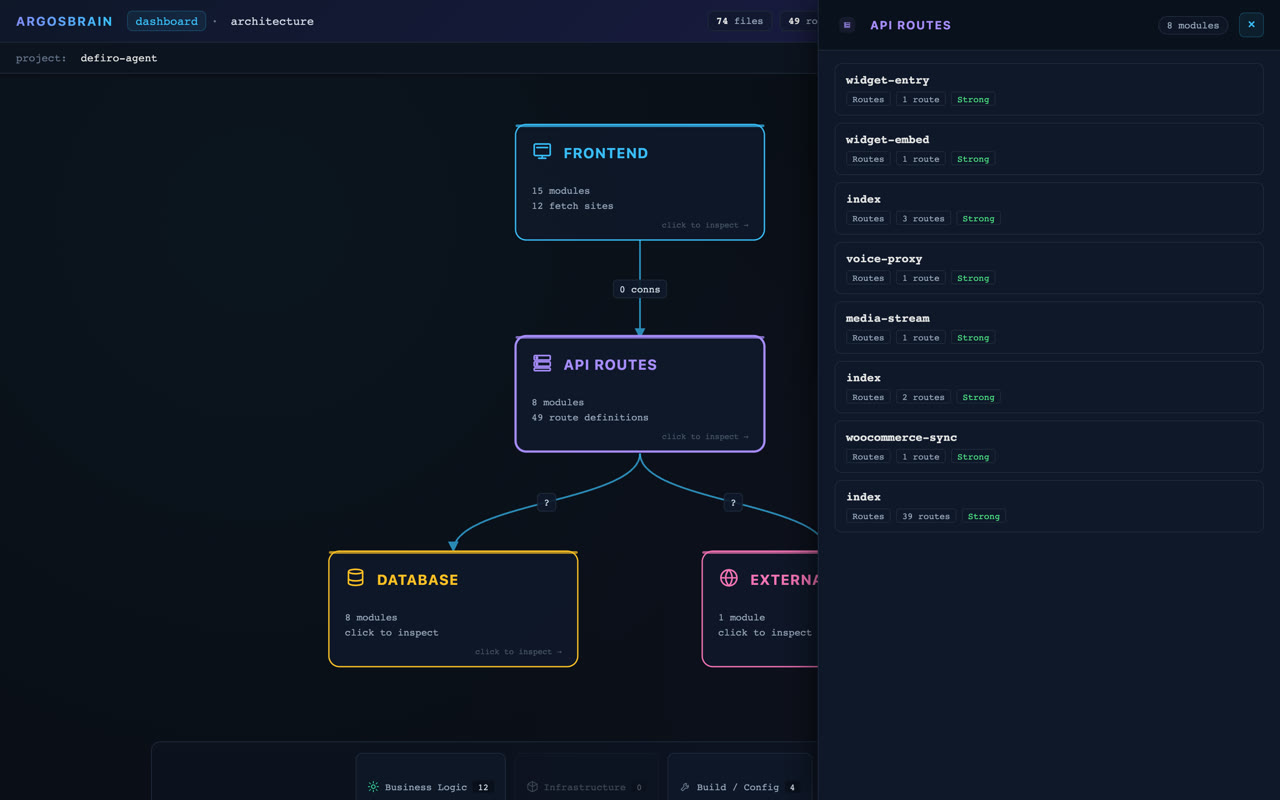
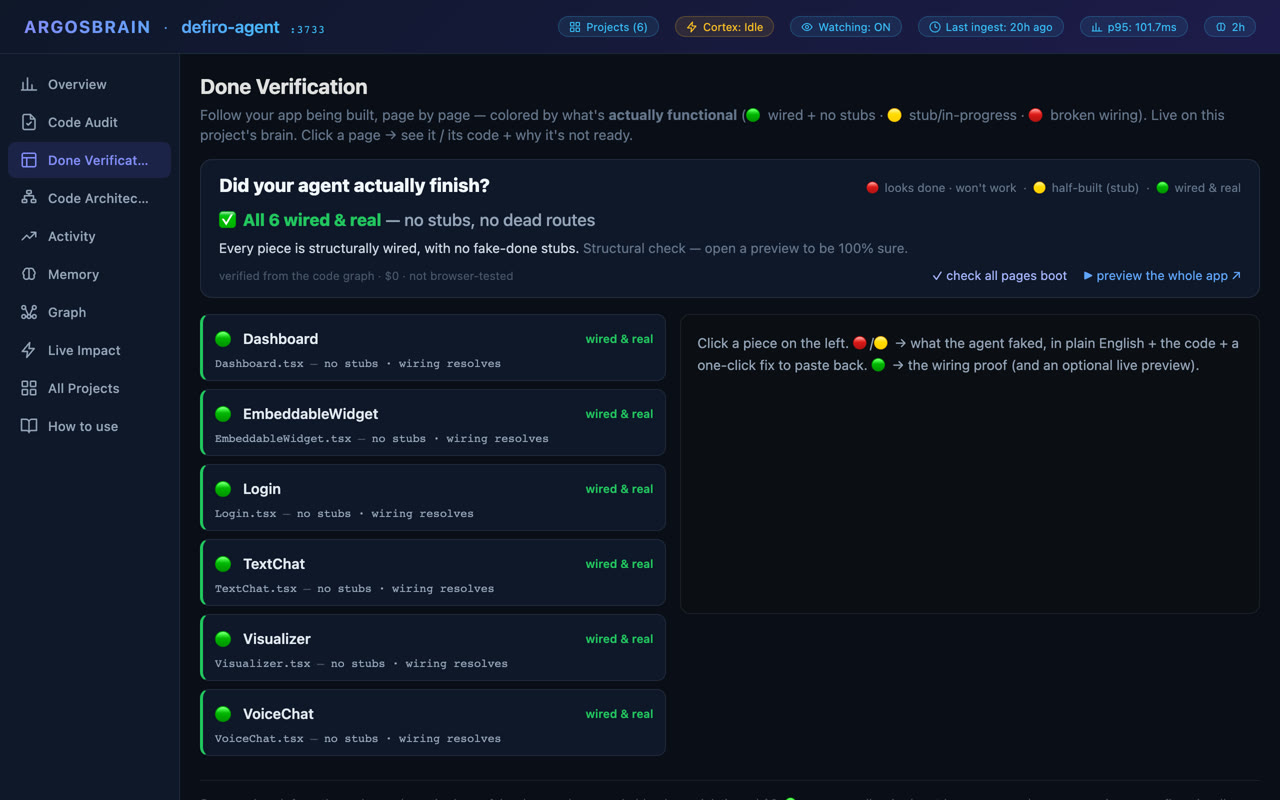
We didn't write these. Claude Opus 4.7 did — unprompted — during a live 1 237-turn coding session on a production Next.js SaaS. These are its own-word notes on what ArgosBrain caught that grep and guesswork missed — the exact structural facts a report is built from. The eighth card (multi-modal) ships in v0.2 — it arrived after the review, so it's ours, labelled as such.
01 / RECALL
The SSRF Discovery
High-recall via call-graph
"The initial audit scoped src/app/api/ and found two SSRF sites. ArgosBrain surfaced four more in src/lib/services/ — the agent had to follow causal edges across directories Grep wasn't pointed at."
— Claude Opus 4.7 · dogfood session · 2026-04-22
2× RECALL VS. GREP
Grep only finds what you point it at — miss the directory, miss the vulnerability. ArgosBrain follows the call graph wherever it leads.
02 / PRECISION
The Buffer Check
Type-safety via exact signature
"Argos returned a CLEAR match: uploadVideoToTikTok(videoBuffer: Buffer, …) takes a Buffer, not a URL. The agent was about to patch the call site as if it accepted a URL — that retrieval prevented a silently-broken commit."
— Claude Opus 4.7 · dogfood session · 2026-04-22
PREVENTED A BAD COMMIT
An AI guessing from a name ships the wrong call. ArgosBrain reads the exact signature — no lookalike can outrank the real one.
03 / CONFIDENCE
The RLS Deletion
Architectural confidence via definitive-no
"Before deleting an RLS-bypassing route I thought was dead, I asked Argos for its callers. It returned NO_CONFIDENT_MATCH — exhaustive over the ingested codebase. Not 'I didn't find any'; 'there are none.' Deleted with confidence, no regression."
— Claude Opus 4.7 · dogfood session · 2026-04-22
SAFE DEAD-CODE CUT
Grep can't prove a negative. ArgosBrain can: “no callers” means none exist — safe to delete, not “I didn't find any.”
04 / REUSE
The Endpoint Reuse
Anti-duplication via structural lookup
"I was about to write a new handler. Argos pulled up the existing one from an older session — same behaviour, already tested. Saved me a duplicate route and the tech debt that comes with it."
— Claude Opus 4.7 · dogfood session · 2026-04-22
NO DUPLICATE HANDLERS
Grep finds text matches but can't tell you two handlers do the same thing. ArgosBrain surfaces the existing one before your AI writes a duplicate.
05 / STYLE
The Pattern Matcher
Style consistency via structural tools
"Before adding a new admin check, Argos surfaced ADMIN_EMAILS as the project's established pattern. The agent used the same convention instead of inventing its own. Tiny detail; compounds over months."
— Claude Opus 4.7 · dogfood session · 2026-04-22
STYLE-CONSISTENT PRS
Most tools don't model your code's conventions at all. ArgosBrain surfaces the established pattern so your AI follows it instead of inventing its own.
06 / SPEED
The Negative Prover
Sub-50ms "nothing exists"
"'Does sanitizeHtml exist in this project?' — answered 'no' in 40ms with confidence 1.0. Grep on 400 files would have taken a full second and left the question ambiguous. The agent stopped hunting for ghosts."
— Claude Opus 4.7 · dogfood session · 2026-04-22
< 50 MS DEFINITIVE NEGATIVES
A model hedges when unsure and keeps hunting. ArgosBrain answers “doesn't exist” with confidence 1.0 — so your AI stops chasing ghosts.
07 / SCOPING
The Tech Lead
ROI estimation via call-graph
"Before committing to a feature, the agent used Argos to map every file a change would touch — six, across three service boundaries. It flagged the effort as disproportionate and deferred the work. A human tech lead would have done the same scope check."
— Claude Opus 4.7 · dogfood session · 2026-04-22
ACCURATE EFFORT ESTIMATES
Scoping a change by hand takes a senior engineer. ArgosBrain maps every file a change touches up front — so the work gets estimated before it starts.
NEW · v0.2
08 / MULTI-MODAL
The Multi-modal Librarian
Images, PDFs, audio — linked to code
"User shared a UI mockup. The LLM interpreted it — 'a 3-step Stripe checkout, Place Order button disabled until terms accepted' — and Argos stored that interpretation linked to checkoutHandler. Two weeks later, the 'why is the button disabled?' question resolved instantly."
1 CALL = IMAGE + CONTEXT + CODE LINK
Your AI interprets a mockup or spec once; ArgosBrain stores that interpretation linked to the exact code it describes — so the “why” survives long after the conversation.